Beschrijvende statistieken
In dit artikel neem ik u mee in de wondere wereld van de statistiek, met name de beschrijvende statistieken, en hoe u dit in Excel kunt gebruiken.
Een gevleugelde uitdrukking luidt:
Er zijn 3 soorten leugens: Een leugentje om bestwil, een grove leugen en statistiek.
Nu kun je met statistiek inderdaad de waarheid enigszins naar je hand zetten maar dan moet je wel goed weten hoe het in elkaar zit. En het begint allemaal met beschrijvende statistiek.
Laten we beginnen met een eenvoudig voorbeeld en aan de hand daarvan een aantal statistische grootheden bepalen. We kijken dan ook naar de standaard statistische functie in Excel die daarbij hoort.
Kijk eens naar de volgende getallen: 3, 3, 4, 5, 6, 7, 8, 8, 8, 9.
Om het gemiddelde uit te rekenen moeten we de getallen bij elkaar optellen en delen door het aantal getallen:
som = 61,
aantal = 10,
gemiddelde = 61 / 10 = 6,1.
Excel heeft hiervoor de volgende (ongetwijfeld) bekende functies: SOM, AANTAL, GEMIDDELDE.
Om iets meer over het gemiddelde ten opzichte van de waarnemingsgetallen en vice versa te kunnen zeggen hebben statisticie de volgende grootheden bedacht:
De mediaan
De mediaan is het middelste waarnemingsgetal (als de waarnemingen gesorteerd staan van klein naar groot). Als er geen middelste waarnemingsgetal is (bij even aantallen is dat zo) dan is de mediaan het gemiddelde van de twee middelste waarnemingsgetallen.
In ons voorbeeld zijn de twee middelste getallen 6 en 7 en is de mediaan dus (6+7)/2=6,5.
De mediaan en het gemiddelde liggen hier dicht bij elkaar, wat doet vermoeden dat de spreiding zal meevallen.
Kwartielen
Er zijn 3 kwartielen en deze worden gebruikt om de groep waarnemingsgetallen te verdelen in 4 groepen. Je kunt dan weer bepalen of de groepen een beetje eerlijk verdeeld zijn.
Het tweede kwartiel is niets anders dan de mediaan.
Het eerste kwartiel is de mediaan van de groep links van de mediaan.
Het derde kwartiel is de mediaan van de groep recht van de mediaan.
In ons voorbeeld is het eerste kwartiel dus 4 en het derde kwartiel is 8.
Excel kent de functie KWARTIEL maar deze geeft niet altijd het gewenste resultaat (dit geldt ook voor de twee opvolgers van de functie: KWARTIEL.INC en KWARTIEL.EXC) omdat deze functies uitgaan van percentielen en die hebben er eigenlijk niets mee te maken.
Modus
De modus is het waarnemingsgetal dat het meeste voorkomt. Zijn er meerdere getallen die hiervoor in aanmerking komen dan bestaat de modus niet.
In ons voorbeeld is de modus 8 omdat de 8 drie keer voorkomt. Stel dat de 4 in ons voorbeeld een 3 zou zijn geweest dan bestaat de modus dus niet.
Excel kent de functie MODUS (oud) en MODUS.ENKELV om de modus te bepalen. Echter zal Excel met deze functie altijd een resultaat geven wat formeel dus niet juist is. Wanneer in ons voorbeeld de 4 een 3 is dan geeft de functie MODUS.ENKELV 3 als modus.
Variantie
Een andere maat voor de spreiding is de variantie. Dit is dus een maat om te kijken hoe de waarnemingsgetallen onderling verschillen.
Om deze te kunnen bepalen moeten we wat werk gaan verzetten.
De eerste stap is om per waarnemingsgetal te bepalen wat het verschil is met het gemiddelde.
In ons voorbeeld krijgen we dan (resp.): -3,1; -3,1; -2,1; -1,1; -0,1; 0,1; 1,9; 1,9; 1,9; 2,9.
Wat nu voor de hand zou liggen is om deze getallen op te tellen en te delen door het aantal (zeg maar een gemiddelde van de afwijkingen).
Maar hier bijt de slang zichzelf in de staart. Als ik de afwijkingen bij elkaar optel dan komt daar nul uit. En dat is logisch!
Om dit te voorkomen moet we af van de tekens (de minnen). De manier om dat te doen is de afwijkingen te kwadrateren.
We krijgen dan: 9,61; 9,61; 4,41; 1,21; 0,01; 0,81; 3,61; 3,61; 3,61; 8,41.
De som van deze afwijkingen in het kwadraat is 44,9. In Excel kan hiervoor de functie DEV.KWAD worden gebruikt.
De variantie krijgen we nu door de som te delen door het aantal. De variantie is dus 44,9/10=4,49.
Deze 4,49 zegt ons dat de reeks waarnemingsgetallen ongeveer zit tussen de 6,1-4,49 en de 6,1+4,49 (6,1 was het gemiddelde), en dat klopt in ons voorbeeld heel aardig.
Nu zijn statistici niet alleen maar leugenaars, ze hebben ook een gevoelige kant. De variantie die we net berekend hebben is eigenlijk te precies. Je moet hier wat “losser” mee omgaan, zo zeggen zij. Je moet niet de variantie van de populatie hebben maar de variantie van een steekproef.
En hier wringt, wat mij betreft, ook meteen de schoen. Want de vraag hierbij is dan: Welke steekproef en wat zijn dan de eisen die aan de steekproef gesteld moeten worden. Op die vraag krijg je geen antwoord.
Om de boel simpel te houden hebben ze gezegd dat de steekproef gewoon eentje minder is!?!?
Dus om de variantie van de steekproef te bepalen moeten we de kwadraatsom delen door het aantal – 1.
Ok, de variantie van de steekproef is dus 44,9/9=4,989. Fantastisch!
De Excel functies om de varianties te berekenen zijn: VAR.P en VAR.S.
Standaard deviatie
Verreweg de belangrijkste beschrijvende statistiek is de standaard deviatie ofwel de standaard afwijking.
Deze maat zegt namelijk iets over de individuele waarnemingsgetallen ten opzichte van het gemiddelde.
Stel dat onze getallen de resultaten zijn van 10 leerlingen die een proefwerk hebben gedaan. Zijn degenen met een 3 nu uitzonderlijk slecht en degene met een 9 uitzonderlijk goed of niet?
Deze vraag kan worden beantwoord met de standaard deviatie.
Maar eerst moeten we deze berekenen.
Dit is vrij eenvoudig als de variantie al bekend is. De standaard deviatie is de wortel van de variantie. In ons voorbeeld dus de wortel van 4,49 = 2,12.
Bedenk dat de variantie, onder meer, bestaat uit kwadraten. Om dit weer ongedaan te maken moeten we de wortel trekken om zo tot een standaard te komen. En dat is precies wat we doen bij het berekenen van de standaard deviatie.
Wat zegt de standaard deviatie ons nu?
Als de waarnemingen “normaal” verdeeld zijn, dan kun je zeggen dan zo’n 68% van de waarnemingen ligt tussen het gemiddelde – standaard deviatie en het gemiddelde + standaard deviatie en dat maar liefst 95% ligt tussen het gemiddelde – 2 * standaard deviatie en het gemiddelde + 2 * standaard deviatie.
Ons 68%-interval is dus [6,1-2,12..6,1+2,12] = [3,98..8,22] en het 95%-interval is [6,1-2*2,12..6,1+2*2,12] = [1,86..10,34].
Je kunt dus zeggen dat de 3-en en de 9 keurig in het 95%-interval liggen en daarmee niet uitzonderlijk zijn. Alles buiten het 95%-interval wordt over het algemeen “bijzonder” gevonden. Sommige statistici werken met een 99%-interval. Dit is het gemiddelde +/- 3 * standaard deviatie.
Overigens is onze populatie van 10 wat aan de kleine kant om normaliteit te kunnen toetsen, maar dat even terzijde.
Bij een normale verdeling wordt dus gekeken naar de intervallen en of de waarnemingen gelijkelijk in de intervallen ten opzichte van het gemiddelde zijn verdeeld. Wanneer je dit in een grafiek zou uitzetten dan krijg je een klok-vorm bij een normale verdeling.
 |
 |
 |
 |
Tot slot wijs ik er nog op dat er uiteraard ook een standaard deviatie van de steekproef bestaat, dit is de wortel uit de variantie van de steekproef.
De Excel functies zijn: STDEV.P en STDEV.S.
Minimum en Maximum
Deze twee statistieken zijn natuurlijk overbekend.
Het minimum is het kleinste waarnemingsgetal en het maximum is het grootste waarnemingsgetal.
In ons voorbeeld is het minimum 3 en het maximum 9.
De Excel functies zijn resp.: MIN en MAX.
Klasses
Er zijn nog steeds statistici die het nuttig vinden om de waarnemingsgetallen in klasses onder te verdelen en dan per klasse het gemiddelde uit te rekenen en eventueel nog andere statistieken per klasse te bepalen. In deze tijd van computers en big-data-analyse is het mij een raadsel waarom je nog met klasses zou werken. In het pre-computer tijdperk was dit inderdaad een nuttige bezigheid om van grote hoeveelheden data af te komen, maar in deze tijd???
Maar om ze toch tegemoet te komen volgt hier een vuistregel:
Het aantal klasses is de wortel van het aantal waarnemingen en de klassebreedte is dan het absolute verschil van het maximum en het minimum gedeeld door het aantal klasses.
Excel kent hier geen functies of voorzieningen voor.
Data statistieken
De Excel-add-in Handigheidjes van HJGSoft kent wel een voorziening om de standaard statistieken van een reeks waarnemingen te bepalen.
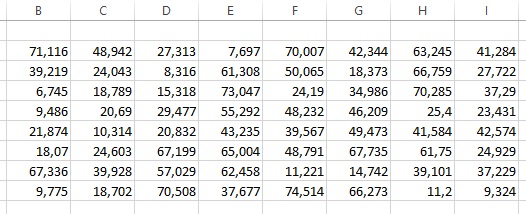
In dit voorbeeld staan 64 metingen, kris kras door elkaar. Voordat de statistieken bepaald kunnen worden moet er eigenlijk eerst worden bepaald wat de significatie van de getallen is. Na een korte beschouwing is dat 1 decimaal. Je wilt dus eigenlijk alle getallen afronden op 1 decimaal en van die getallen de statistieken bepalen.
Klik in de tab HJGSoft van het lint op de knop Data Statistieken.
U krijgt dan het volgende scherm:
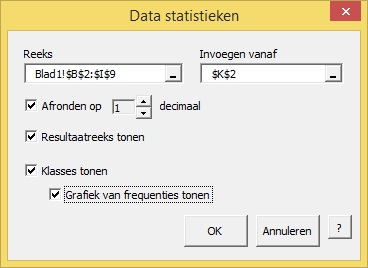
De opties spreken voor zich (denk ik) en kan in dit voorbeeld als volgt worden ingevuld:
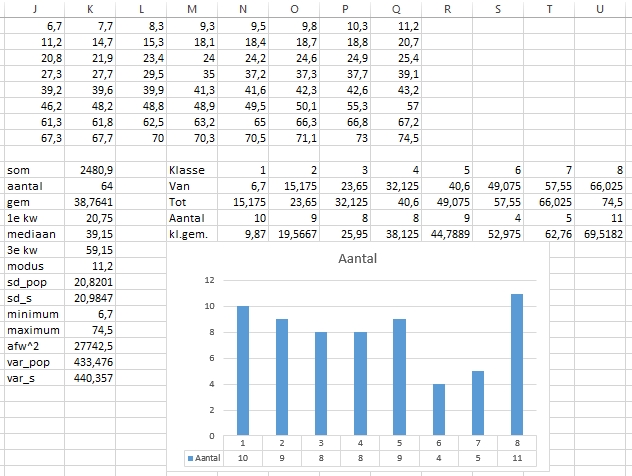
Klik op de knop OK voor het resultaat:
Data Statistieken is onderdeel van de Excel-Handigheidjes van HJGSoft. Meer informatie vindt u op de pagina Excel. U kunt de tool downloaden op de Download-pagina en kunt deze daarna gratis 10 dagen uitproberen.
Opmerking: De verwijzingen naar HJGSoft zijn niet meer actief omdat HJGSoft niet meer actief is. Wellicht dat in de toekomst een deel van de functionaliteiten op deze site gepubliceerd gaat worden.